A. Answer
- 如果两个以上的函数要对同一个通道进行操作,这两个函数在不同的协程中并发运行会不会出现抢夺通道的情况,比如读和写的函数,还没有写,就先读了?
- 为什么一定通道写完后一定要有一个通道关闭的操作?
- 通道的缓冲区有什么作用?
- select 是用来干什么的?
B. 场景
请完成协程和管道协同工作的案例,具体要求:
- 开启一个writeData协程,向管道中写入50个整数.
- 开启一个readData协程,从管道中读取writeData写入的数据。
- 注意: writeData和readDate操作的是同一个管道
- 主线程需要等待writeData和readDate协程都完成工作才能退出
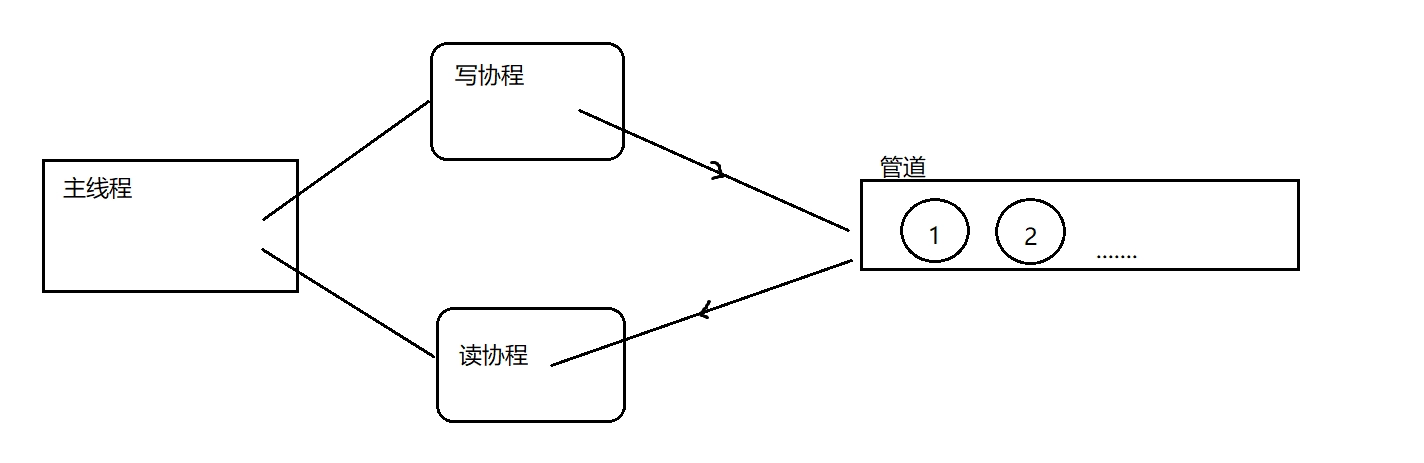
C. 原理图
D. 代码
| |
E. 思路与疑问
使用 Goroutine 进行并发:
- Goroutine:有两个 goroutine,分别是
writeData和readData,它们负责将数据写入和从intChanchannel 中读取数据。 - 使用 WaitGroup 进行同步:使用了
sync.WaitGroup来确保主函数在这两个 goroutine 完成之前不会退出。这是通过调用wg.Add(2)来设置需要等待的 goroutine 数量,并在每个 goroutine 中调用wg.Done()来表示完成。
Channel 操作:
- 创建 Channel:
intChan是一个带有缓冲区大小为 50 的 channel,这意味着它可以容纳最多 50 个整数而不会阻塞。 - 写入 Channel:
writeData函数将整数 1 到 50 写入 channel。写完所有数据后,它使用close(intChan)关闭 channel。关闭 channel 很重要,因为它向readData函数发出信号,表明不会再发送数据。 - 读取 Channel:
readData函数使用range的for循环从 channel 中读取数据,这个循环会一直持续到 channel 被关闭并且所有数据都被读取完。
潜在问题和安全性:
- Channel 关闭:由于在写入所有数据后关闭了 channel,所以
readData函数不会遇到“向已关闭的 channel 发送数据”的错误。在readData中的range循环在 channel 被关闭并且所有数据被消费后会正常退出。 - 缓冲区大小:缓冲区大小为 50,正好匹配要写入的整数数量,这意味着只要缓冲区没有被超过,
writeData函数就不会阻塞等待readData函数消费数据。 - 并发安全性:Go 中的 channel 是为并发使用而设计的安全的。只要遵循一个 goroutine 写入和另一个读取的模式,并且正确关闭 channel,就不会遇到并发问题。
E.1. 疑问
如果说我还没有存入数,readData函数就先开始运行,导致读取空通道;再比如才存入一个数,已经进行第二次读的操作了。这些情况会不会导致 error ?
不会
channel 通道有一个阻塞的特性。如果按照假设 readData 函数在 channel 通道为空时会自动阻塞进行等待,直到有数据被写入。
并发的顺序性,在并发环境中,这两个函数的执行顺序并不固定,由于 channel 的阻塞特性,程序会自动协调读写的顺序。
所以程序中有一个重点在于关闭通道,这可以给接收方发出信号,表示不会有新的数据写入通道,这样子,接收方可以通过检测通道的关闭状态来安全地推出读取循环。关闭通道是确保程序正确运行和资源释放的一个重要步骤。
F. 通道
在 Go 语言中,管道(channel)是用于在不同 goroutine 之间传递数据的工具。管道有两种类型:无缓冲和有缓冲。
- 无缓冲管道:无缓冲管道在发送和接收操作之间没有缓冲区,因此发送操作会阻塞,直到有接收者准备好接收数据。这意味着如果在一个 goroutine 中向无缓冲管道发送数据,而没有其他 goroutine 从该管道接收数据,发送操作就会阻塞,程序会暂停在这一点上,直到有接收者出现。
- 有缓冲管道:有缓冲管道允许在没有接收者的情况下存储一定数量的数据。只有当缓冲区满时,发送操作才会阻塞。因此,如果我们向一个有缓冲的管道发送数据,而缓冲区已经满了,并且没有接收者来消费这些数据,发送操作也会阻塞。
缓冲区作用
- 提高并发效率:缓冲区允许发送方和接收方在不同步的情况下继续工作。发送方可以在缓冲区未满时继续发送数据,而不必等待接收方处理完当前数据。这提高了程序的并发效率。
- 减少阻塞:有缓冲区的通道可以在一定程度上减少发送方的阻塞。当缓冲区未满时,发送操作不会阻塞,只有在缓冲区满时才会阻塞等待接收方读取数据。
- 控制数据流:缓冲区的大小可以用来控制数据流的速率。通过调整缓冲区的大小,可以在一定程度上控制发送和接收之间的数据流动速度。
- 解耦发送和接收:缓冲区使得发送和接收操作可以在不同步的情况下进行,从而解耦了发送方和接收方的执行顺序。
因此,管道阻塞的原因在于 Go 的并发模型设计:它确保数据在发送和接收之间的同步性,以避免数据丢失或不一致的情况。通过这种机制,Go 可以有效地管理并发操作中的数据传递。
G. Select
在 Go 语言中,select 语句用于在多个通道操作中进行选择。它的作用类似于 switch 语句,但专门用于处理通道的发送和接收操作。select 语句会阻塞,直到其中一个通道可以进行操作为止。
G.1. 作用
- 多路复用:
select允许一个 goroutine 同时等待多个通道操作。它会选择其中一个可以进行的操作执行,如果有多个通道同时准备好,select会随机选择一个。 - 非阻塞操作:通过结合
default分支,select可以实现非阻塞的通道操作。如果没有通道准备好,select会执行default分支中的代码。 - 超时控制:可以使用
select实现超时机制。例如,通过time.After创建一个超时通道,当超过指定时间后,该通道会接收到一个值,从而触发select的相应分支。
G.2. 应用场景
- 同时监听多个通道:在需要同时从多个通道接收数据的情况下,
select可以有效地管理这些操作。 - 实现超时机制:在等待通道操作时,使用
select可以设置一个超时时间,以防止无限期阻塞。 - 处理通道关闭:
select可以用于检测通道是否关闭,从而安全地退出循环或进行其他处理。
G.3. 例子
G.3.1. 同时监听多个通道
| |
在这个例子中,select 用于同时监听 ch1 和 ch2,并根据哪个通道先接收到数据来决定执行哪个分支。
G.3.2. 实现超时机制
| |
在这个例子中,select 用于实现超时机制。如果在 2 秒内没有从 ch 接收到数据,程序将输出“操作超时”。
G.3.3. 非阻塞通道操作
| |
在这个例子中,select 使用 default 分支来实现非阻塞操作。如果没有数据可接收,程序将执行 default 分支。
H. 利用 defer+recover 机制处理错误
利用 defer+recover 机制处理错误,这样做的目的和好处在于,就算是某个协程中出现了 panic,导致该部分程序崩溃也不会影响到主线程,主线程可以继续执行。
| |
结果